
Tipos de datos en C++¶
Sistemas numéricos¶
Uno de los datos esenciales que se manejan en programación son los números.
Los números al igual que todos los demás datos se almacenan en la memoria en forma de sucesiones binarias de 0 y 1 llamadas bits.
Cada conjunto de 8 bits se denomina byte.
La fórmula para determinar cuantos dígitos se pueden representar con n bits es 0 ~ 2^n – 1. Por ejemplo:
- 1 bit 0~2^1-1 = 0~1 (2)
- 2 bits 0~2^2-1 = 0~3 (4)
- 3 bits 0~2^3-1 = 0~7 (8)
- 4 bits 0~2^4-1 = 0~15 (16)
- 8 bits (1 byte) 0~2^8-1 = 0~255 (256)
- 16 bits (2 bytes) 0~2^16-1 = 0~65.534 (65.535)
- 32 bits (4 bytes) 0~2^32-1 = 0~4.294.967.295 (4.294.967.296)
- 64 bits (8 bytes) 0~2^64-1 = 0~18.446.744.073.709.551.615 (18.446.744.073.709.551.616)
Todo esto sería utilizando la conversión binario-decimal de números conocida como base 10 (decimal), pero los números se pueden representar en diferentes bases, por ejemplo base 8 (octal), base 16 (hexadecimal)…
Esta lista muestra la conversión de los números de 0 a 15 en binario, decimal y hexadecimal:
0000 00 0
0001 01 1
0010 02 2
0011 03 3
0100 04 4
0101 05 5
0110 06 6
0111 07 7
1000 08 8
1001 09 9
1010 10 A
1011 11 B
1100 12 C
1101 13 D
1110 14 E
1111 15 F
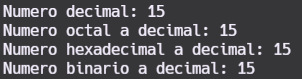
En C++ para definir un número entero en base 10 podemos hacerlo en diferentes sistemas:
#include <iostream>
int main()
{
int num1 = 15; // Base decimal
int num2 = 017; // Base octal
int num3 = 0x0F; // Base hexadecimal
int num4 = 0b00001111; // Base binaria
std::cout << "Numero decimal: " << num1 << std::endl;
std::cout << "Numero octal a decimal: " << num2 << std::endl;
std::cout << "Numero hexadecimal a decimal: " << num3 << std::endl;
std::cout << "Numero binario a decimal: " << num4 << std::endl;
return 0;
}
En conclusión:
- En la memoria los datos se almacenan en grupos de bits con 0 y 1.
- Una sucesión agrupada de 8 bits en la memoria se denomina byte.
- Cuanto más grande es el rango de datos a representar más bits necesitamos.
- El sistema hexadecimal es una forma intuitiva de representar conjuntos de 16 bits.
Números enteros y variables¶
Un número entero es un tipo de dato para representar números del sistema decimal. En C++ la palabra para definir un entero es int y ocupan generalmente 4 bytes en la memoria. Podemos consultar el tamaño de un entero en bytes mediante la función sizeof:
std::cout << sizeof(int);
Un número, y los demás tipos de datos, se pueden almacenar en la memoria del programa para manipularlos. Para ello se utilizan las variables, un espacio en la memoria que reservamos mediante un nombre y el tipo de dato que deseamos almacenar en ella:
int numero; // Inicialización de una variable entera
Una vez tenemos el espacio reservado podemos asignarle el valor:
int numero; // Inicialización de una variable entera
numero = 100; // Asignación de un número a la variable
Podemos realizar la inicialización y asignación en una única instrucción:
int numero = 100; // Inicialización y asignación
Esto se puede realizar sin la igualdad mediante paréntesis o llaves:
int numero (100); // Inicialización con constructor C++17
int numero {100}; // Inicialización uniforme
Por defecto un entero sin asignar tiene un valor de 0:
Ya que hablamos de asignaciones, podemos asignar múltiples variables en una única línea:
int num1{100}, num2{200};
Y también podemos asignar a una variable una operación a partir de otros datos, siempre y cuando el resultado sea del mismo tipo que asignamos, ya sea literalmente o mediante variables:
int res{num1 + num2 + 300};
std::cout << res;
Si intentamos asignar un valor mayor de 4 bytes o un número fraccionario (mediante una coma), dará error:
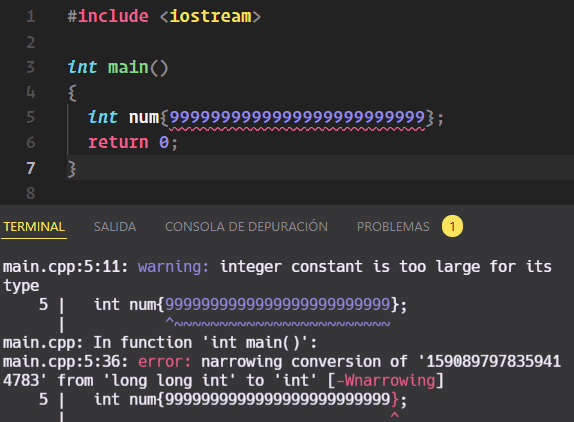
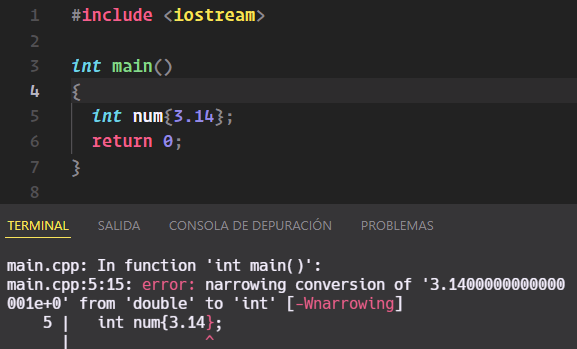
Sin embargo sí es posible realizar una conversión de tipo fraccionario a entero con redondeo de medio decimal implícito mediante el operador =:
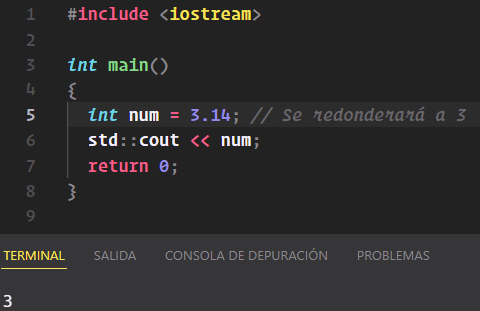
Todavía hay mucho que hablar sobre los números, seguiremos próximamente.
Modificadores de enteros¶
En el lenguaje C++ encontramos una serie de funcionalidades conocidas como modificadores que permiten cambiar el funcionamiento de un tipo de dato.
Por ejemplo, un modificador básico de los números enteros es la negación –, que nos permite cambiar el signo positivo de un número a un signo negativo:
int num {-99};
¿Cómo puede ser esto? Pues porque los enteros int reciben un modificador implícito llamado signed que les indica que pueden ser positivos o negativos:
signed int num {-99}; // Por defecto tienen signo
Esto implica que también pueden no tener signo, lo cuál se indica mediante el modificador unsigned, y que en esta ocasión al intentar almacenar en él un negativo dará error:
unsigned int num {-99}; // Entero sin signo negativo dará error
¿Qué diferencia hay entre un entero con signo y uno sin signo?
Ya sabéis que un entero int ocupa en memoria 4 bytes, eso son (4*8) 32 bits y por tanto podemos representar cualquier número en el rango (0~32^2-1) **de **[0, 4.294.967.295].
Pues bien, esto sería en el caso en que un número entero sea unsigned, porque si fuera signed en realidad tenemos que dividir el rango en dos partes, los números con signo negativo y los números con signo positivo. Por tanto tendríamos 2.147.483.648 negativos y la misma cantidad de positivos, contando el cero como un positivo y por tanto teniendo el rango de [-2.147.483.648, 2.147.483.647].
En C++ existen dos constantes (una especie de variables no modificables por el usuario), que almacenan el número entero mínimo y máximo con signo:
std::cout << INT_MIN << ", " << INT_MAX;
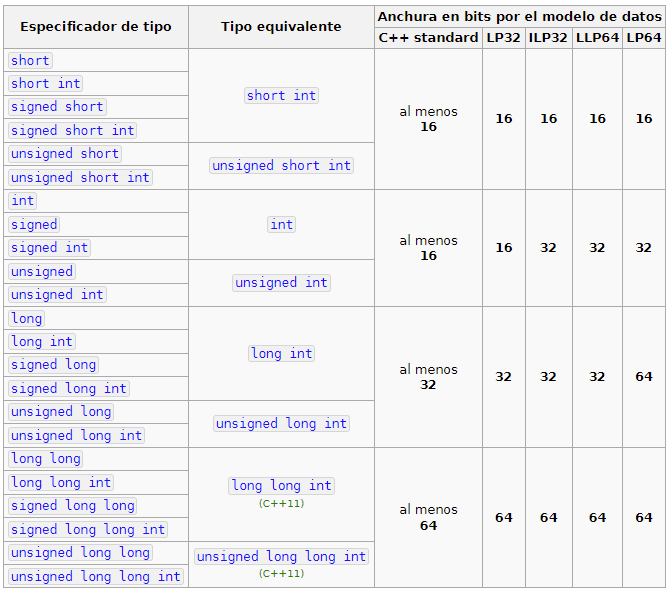
También existen dos tipos que pueden utilizarse como modificadores llamados short y long para optimizar el uso de la memoria dependiendo del rango de números que necesitemos almacenar.
En la web https://es.cppreference.com/w/cpp/language/types podemos consultar la siguiente tabla donde se muestran todas las combinaciones de short, int, long con y sin signo:
Números fraccionarios¶
Dejando de lado los números enteros, también podemos trabajar con números fraccionarios, cuyos tipos se conocen como tipos de punto flotante y encontramos esencialmente tres dependiendo de la precisión decimal que necesitemos:
float: 4 bytes y 7 dígitos de precisión, se indican con unafal final.double: 8 bytes y 15 dígitos de precisión, son el tipo fraccionario por defecto.long double: 16 bytes y precisión mayor que un double, se indican con unaLal final.
std::cout << sizeof(float) << std::endl; // 4 bytes
std::cout << sizeof(double) << std::endl; // 8 bytes
std::cout << sizeof(long double) << std::endl; // 16 bytes
La precisión es el número de dígitos decimales que se pueden representar detrás del punto:
float num1{1.0011223344556677889f};
double num2{1.0011223344556677889};
long double num3{1.0011223344556677889L};
std::cout << num1 << std::endl; // 1.00112
std::cout << num2 << std::endl; // 1.00112
std::cout << num3 << std::endl; // 1.00112
La función std::cout limita por defecto la precisión a 6 dígitos, podemos cambiarla importando la biblioteca <iomanip> y usando la función std::setprecision antes de mostrar el valor.
Lo curioso del ejemplo es que los tipos float y long double, a partir de los 7 y 15 dígitos de precisión, rellenan la salida hasta los 20 dígitos con números aparentemente aleatorios:
std::cout << std::setprecision(20);
std::cout << num1 << std::endl; // 1.0011223554611206055
std::cout << num2 << std::endl; // 1.0011223344556678949
std::cout << num3 << std::endl; // 1.0011223344556677889
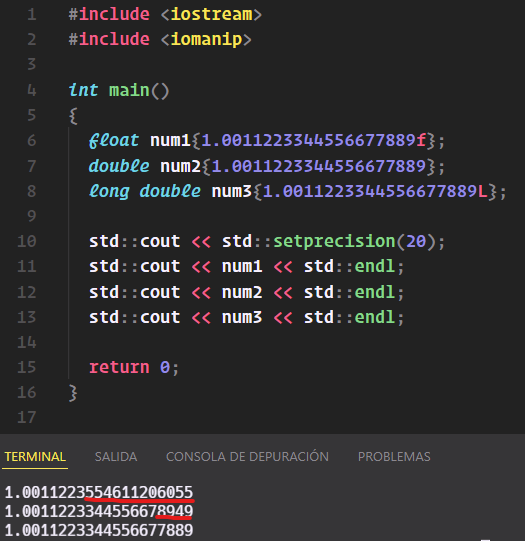
En realidad no son aleatorios, pero para entender la razón por la que sucede esto habría que remitirnos al estándar IEEE 754 donde se explica el funcionamiento y gestión de los números en coma flotante, algo demasiado complejo como para explicarlo aquí.
Cabe mencionar que a parte de la notación fija, los números fraccionarios también permiten la notación científica con exponentes, tanto positivos como negativos:
double num1{123e6}; // 123 * 10^6 => 123000000
double num2{123e-6}; // 123 * 10^-6 => 0.000123
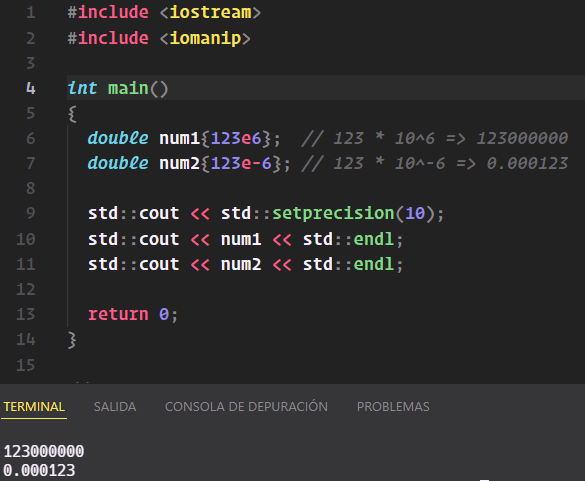
Un par de curiosidades para terminar.
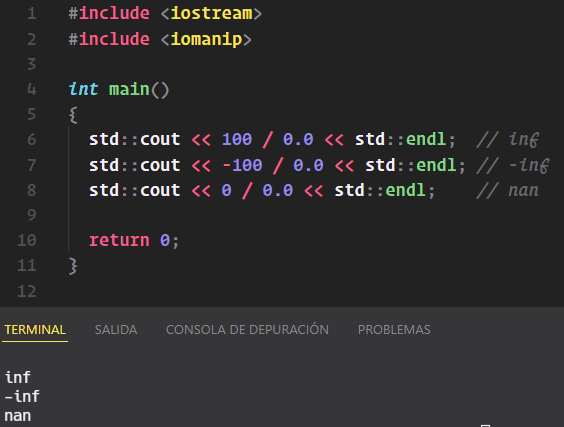
Ya vimos que dividir un número entero entre cero provoca un error que finaliza la ejecución:
std::cout << 100 / 0 << std::endl; // Error
Sin embargo, si en lugar de cero usamos un fraccionario 0.0, nos devolverá algo llamado inf (infinito):
std::cout << 100 / 0.0 << std::endl; // inf
Según mis conocimientos una división entre cero es indeterminada y no infinita, pero al parecer esto responde al hecho de poder determinar el signo, pues si el dividendo es negativo lo que se devuelve es -inf:
std::cout << -100 / 0.0 << std::endl; // -inf
Por último, si dividimos 0 entre 0.0, el sistema devolverá nan (not a number), entendible ahora sí como un resultado indeterminado:
std::cout << 0 / 0.0 << std::endl; // nan
Para más información echad un vistazo a https://es.wikipedia.org/wiki/IEEE_754.
Valores booleanos¶
Otro tipo de dato esencial en la programación es el que sirve para representar un valor lógico o racional con únicamente dos opciones: verdadero y falso.
En C++ las palabras reservadas para estos valores son true y false respectivamente:
std::cout << true << std::endl; // Devuelve 1 al imprimirlo
std::cout << false << std::endl; // Devuelve 0 al imprimirlo
Su tipo de dato recibe el nombre de bool:
bool encendido{false};
std::cout << encendido << std::endl;
Utilizando el operador de negación ! podemos negar un booleano, siendo no verdadero igual a falso y no falso igual a verdero:
bool encendido{false};
std::cout << !encendido << std::endl;
Este tipo ocupa 1 byte en la memoria:
std::cout << sizeof(bool) << std::endl;
Como ya sabemos 1 byte son 8 bits (2^8=256 posibilidades) mientras que para almacenar las dos posibilidades de un booleano sería suficiente con 1 bit (0 y 1), esto implica que este tipo no sea precisamente eficiente respecto al espacio que ocupa.
Por último comentar dos opciones que nos permiten configurar la representación en la salida:
std::cout << std::boolalpha; // Se imprimirán como true y false
std::cout << std::noboolalpha; // Se imprimirán como 1 y 0
Caracteres y texto¶
Otro tipo de dato esencial es el que suponen los símbolos de escritura, llamados caracteres.
En C++ el tipo de dato para almacenar un carácter recibe el nombre de char y su tamaño en la memoria es de 1 byte, esto implica que puede almacenar hasta 256 posibilidades, cada una para un símbolo:
std::cout << sizeof(char) << std::endl;
Los caracteres que se pueden representar no son adrede, sino que se encuentran establecidos en el código ASCII https://en.cppreference.com/w/cpp/language/ascii:
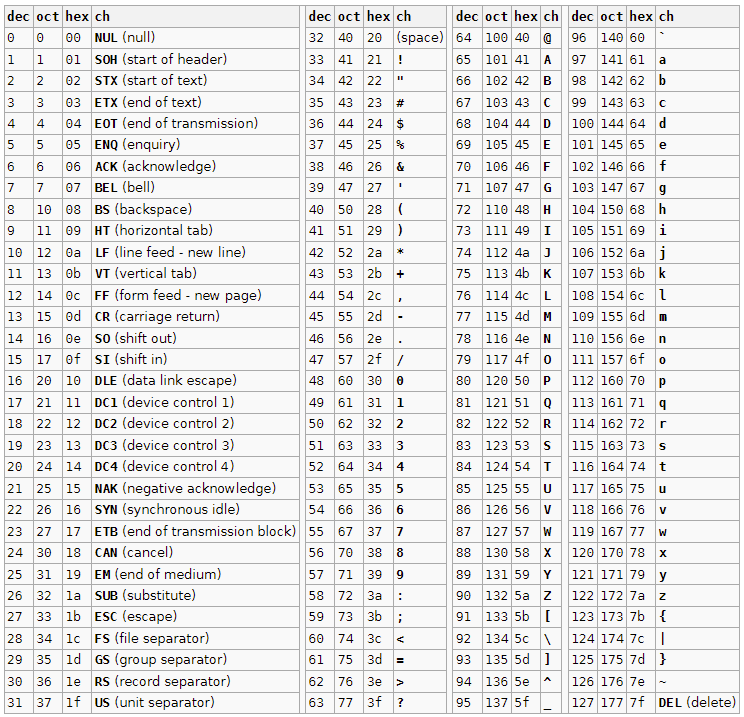
Cada símbolo tiene un número entero asociado, a través del cuál podemos consultar el respectivo carácter:
char valor{65}; // Código ASCII del carácter 'A'
std::cout << valor << std::endl;
Aunque más allá de trabajar con el número a nosotros nos interesará trabajar con los propios caracteres, definidos entre comilla simple:
char valor{'A'};
std::cout << valor << std::endl;
Si nos fijamos en la tabla veremos que existen los caracteres en mayúscula y minúscula, eso es obvio dado que son símbolos distintos. Además también están representados los números naturales como caracteres de escritura, que no debemos de confundir con los tipos de datos numéricos.
Por cierto, una curiosidad es que, si os fijáis los símbolos numéricos tienen un valor decimal menor que las mayúsculas y a su vez estas menor que las minúsculas. Eso explica porqué podemos comparar si un carácter es mayor que otro en función de su número en la tabla:
std::cout << ('a' > 'A') << std::endl; // Devuelve un 1 (true)
Como 'a' tiene un valor de 97 y 'A' 65, al ser 97 mayor que 65 el sistema devuelve 1 en la comparación, haciendo referencia a que ésta es verdadera.
ASCII es uno de los primeros sistemas de codificación para representar texto en las computadoras, el problema es que solo está pensado para representar texto en idioma inglés, por lo que símbolos específicos latinos y otras lenguas no funcionarán y resultarán en un mal funcionamiento del sistema de codificación:
char valor{'á'}; // Error
En la actualidad un sistema de codificación más globalizado es el Unicode que incluye diferentes formas de codificación como UTF-8, UTF-16 y UTF-32.
Si bien en C++ podemos trabajar con Unicode, esto es un tanto complejo, ya que estas tablas son muy extensas y además hay que configurar la salida de datos para decodificar los símbolos y todo esto también depende del sistema operativo.
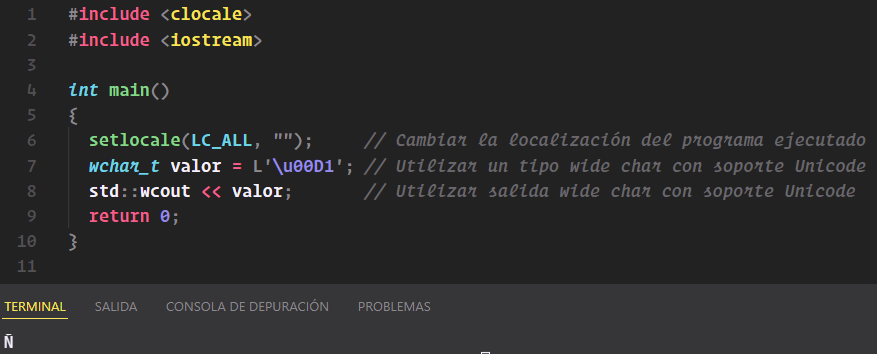
Por curiosidad, algo como almacenar y mostrar un carácter 'Ñ' (cuyo código según la tabla Unicode es 00D1) en Windows 11 requeriría lo siguiente:
#include <clocale>
#include <iostream>
int main()
{
setlocale(LC_ALL, ""); // Cambiar la localización del programa
wchar_t valor = L'\u00D1'; // Tipo wide char con soporte Unicode
std::wcout << valor; // Salida wide char con soporte Unicode
return 0;
}
Cuyo resultado sería el siguiente:
¿Y cómo se almacena no solo un carácter sino varios para representar un texto? Pues los textos, conocidos como cadenas de caracteres, son tradicionalmente arreglos (sucesiones) de múltiples caracteres, un tema que exploraré más adelante.
Tipo automático¶
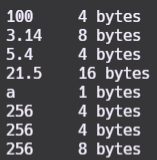
Siempre que definimos una variable debemos indicar el tipo de dato para almacenar el espacio necesario en la memoria, sin embargo desde C++11 podemos dejar al propio lenguaje deducir el tipo de dato a partir del valor literal asignado durante la definición.
auto var1 {100}; // int
auto var2 {3.14}; // double
auto var3 {5.4f}; // float
auto var4 {21.5l}; // long double
auto var5 {'a'}; // char
std::cout << var1 << "\t" << sizeof(var1) << " bytes" << std::endl;
std::cout << var2 << "\t" << sizeof(var2) << " bytes" << std::endl;
std::cout << var3 << "\t" << sizeof(var3) << " bytes" << std::endl;
std::cout << var4 << "\t" << sizeof(var4) << " bytes" << std::endl;
std::cout << var5 << "\t" << sizeof(var5) << " bytes" << std::endl;
También podemos indicar mediante sufijos si queremos números enteros con o sin signo:
auto var6 { 256u}; // unsigned int
auto var7 { 256ul}; // unsigned long
auto var8 { 256ll}; // unsigned long long
std::cout << var6 << "\t" << sizeof(var6) << " bytes" << std::endl;
std::cout << var7 << "\t" << sizeof(var7) << " bytes" << std::endl;
std::cout << var8 << "\t" << sizeof(var8) << " bytes" << std::endl;
Este sería el resultado:
Cabe mencionar que si dejamos que el sistema defina el tipo y le asignamos un sufijo unsigned, si sobrescribimos el valor con un negativo, resultará en un funcionamiento no espero del dato:
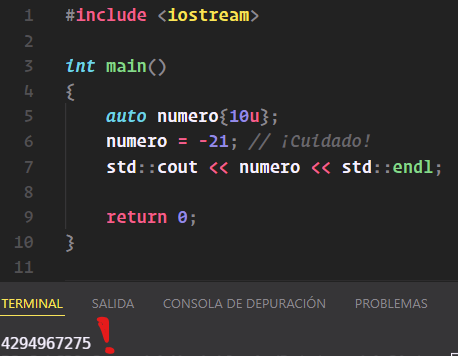
auto numero{10u};
numero = -21; // ¡Cuidado!
std::cout << numero << std::endl;
También si establecemos un tipo como un carácter y luego lo sobrescribimos por algo como un flotante:
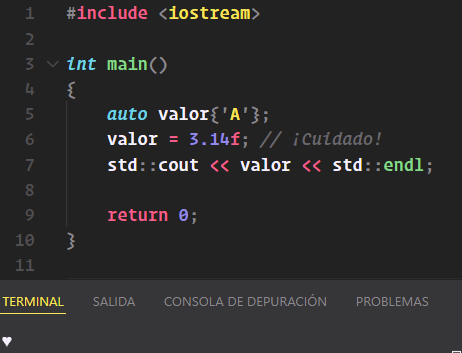
auto valor{'A'};
valor = 3.14f; // ¡Cuidado!
std::cout << valor << std::endl;
En este caso se devolvería lo siguiente:
En conclusión este tipo es muy cómodo, pero debemos tener cuidado con sus valores de sobreescritura.
Ámbito de las variables¶
El ámbito de una variable es el espacio donde se encuentra accesible dentro del programa. Básicamente hay dos tipos de ámbito: local y global.
Cuando se define una variable, ésta existe localmente dentro de su bloque {}:
#include <iostream>
int main()
{
{
int numero{10}; // esta variable local
std::cout << numero << std::endl; // existe en este bloque
}
std::cout << numero << std::endl; // pero aquí no existe
return 0;
}
La variable definida también será accesible por todos los bloques dentro de este bloque, diremos que su ámbito abarca el bloque de su definición y todos sus bloques anidados:
#include <iostream>
int main()
{
int numero{10}; // esta variable de la función main
{
std::cout << numero << std::endl; // existe en este bloque
}
std::cout << numero << std::endl; // también existe en este
return 0;
}
Dado que la función main es un bloque, si creamos otra función, las variables de cada bloque no serán accesibles entre ellas, de hecho podrían tener el mismo nombre pues existen paralelamente en la memoria:
#include <iostream>
void hola()
{
int numero{999}; // variable numero en la funcion hola
std::cout << numero << std::endl; // numero 99
}
int main()
{
int numero{10}; // variable numero en la funcion main
hola(); // ejecutamos la función
std::cout << numero << std::endl; // numero 10
return 0;
}
Sin embargo, si definimos una variable fuera de ambas funciones su ámbito se considerará global y podrá ser manipulable por ambas:
#include <iostream>
int numero{345}; // variable global
void hola()
{
std::cout << numero << std::endl; // numero 345
}
int main()
{
hola();
std::cout << numero << std::endl; // numero 345
return 0;
}
Pese a todo, si una variable local tiene el mismo nombre que una variable global, tendrá prioridad dentro del bloque y la global dejará de ser accesible:
#include <iostream>
int numero{345}; // variable global
void hola()
{
int numero{999};
std::cout << numero << std::endl; // numero 999
}
int main()
{
hola();
std::cout << numero << std::endl; // numero 345
return 0;
}
Tipos de conversiones¶
Las conversiones implícitas son aquellas hechas por el compilador sin la intervención del propio programador. Se realizan al tipo mayor que interviene en la expresión, por ejemplo la operación entre un int y un float se almacenará en un float y entre un double y un float se almacenará en un double:
auto num1 = 12 * 5.0f;
std::cout << sizeof(num1) << std::endl; // float
auto num2 = 12.0 * 5.0f;
std::cout << sizeof(num2) << std::endl; // double
También es posible forzar una conversión implícita mediante el tipo de dato. Por ejemplo, una suma entre dos double en un int, almacenará el resultado truncando la parte fraccionaria:
double num1 = 5.25, num2 = 10.5;
int res = num1 + num2;
std::cout << res << std::endl; // 15.75 -> 15
Por otra parte tenemos las conversiones explícitas indicadas por el programador. Tradicionalmente en C se indica el tipo resultante del dato justo delante:
double num = 15.75;
std::cout << (int)num << std::endl; // 15.75 -> 15
Este tipo de conversiones son inseguras y en C++ se recomienda utilizar la función static_cast haciendo uso de templates:
double num = 15.75;
std::cout << static_cast<int>(num) << std::endl; // 15.75 -> 15
La ventaja de usar static_cast es que si la conversión no es posible se lanzará un error que podría capturarse para actuar en consencuencia.
Derivado de estas conversiones pueden ocurrir dos situaciones conocidas como overflow y underflow.
Overflows y underflows¶
Cuando intentamos guardar en una variable un dato con un tamaño mayor del que ésta permite ocurre un overflow o desbordamiento superior. Por el contrario, si intentamos guardar un dato con un tamaño menor del que permite ocurre un underflow o desbordamiento inferior.
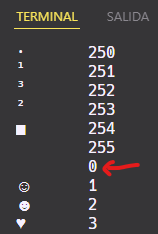
En el siguiente ejemplo podemos observar cómo se comporta una variable char con un rango entre [0, 255] de posibilidades, cuando intentamos almacenar en ella un valor mayor que 255:
#include <iostream>
int main()
{
unsigned char caracter{250}; // Rango char {0, 255}
for (int i = 0; i < 10; i++)
{
std::cout << caracter << "\t"
<< static_cast<int>(caracter) << std::endl;
caracter++;
}
}
Lo que ocurre es ni más ni menos que un overflow, un reinicio a 0 para el 256 y así sucesivamente:
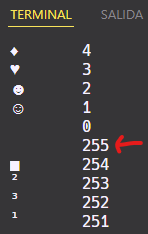
El mismo caso pero por abajo ocurrirá a la inversa, un underflow, pasando de 0 a 255:
#include <iostream>
int main()
{
unsigned char caracter{4}; // Rango char {0, 255}
for (int i = 0; i < 10; i++)
{
std::cout << caracter << "\t"
<< static_cast<int>(caracter) << std::endl;
caracter--;
}
}
Es muy importante tener en cuenta esta situación en las conversiones entre tipo ya que en estos casos no ocurrirá un error y simplemente se tratará el desbordamiento como un reinicio del tamaño.
Última edición: 08 de Mayo de 2022